
While deploying AI/ML workloads, many times you have seen either CUDA/OPENCL SDK or runtimes in your container images. Why at all these SDKs or runtimes even needed for my AI/ML workload? What are these images?
To answer these queries, we have to understand HPP (Heterogenous Parallel Programming/Processing)
Heterogeneous Parallel Programming (HPP)
Heterogeneous Parallel Programming is a specialized approach that leverages both CPUs and GPUs to optimize system performance. By dividing tasks between these two processing units, HPP enables CPUs to focus on general tasks while GPUs handle compute-intensive operations. This collaborative approach significantly enhances overall system efficiency and speed.
After learning HPP technology like CUDA, OpenCL, or C++AMP, you can improve the speed and efficiency in various fields.
Applications of HPP in various industry domains:
a) Scientific work like Physics, Chemistry, and space study.
b) Financial tasks like stock market calculations.
c) Creating scientific visuals in medicine, astronomy, or cars.
d) Making creative visuals for TV, movies, and web ads.
e) Designing with 3D software like AutoCAD or Blender.
f) Developing all types of 3D video games.
g) Applying to graphics projects on computers.
h) Working with digital images.
i) Enhancing security through encryption methods.
j) Handling audio, video, and other media files.
Understanding the Role of HPP in AI and ML:
Virtually all AI/ML applications rely on large datasets for training. To develop AI with these data, different kinds of LLMs are utilized.
Introduction to Large Language Models (LLMs)
Large Language Models (LLMs) are sophisticated artificial intelligence (AI) systems designed to process, understand, and generate human language. These models leverage deep learning techniques, specifically transformer architectures, and are trained on vast datasets to perform a variety of natural language processing (NLP) tasks. This includes applications such as language translation, text summarization, and content creation.
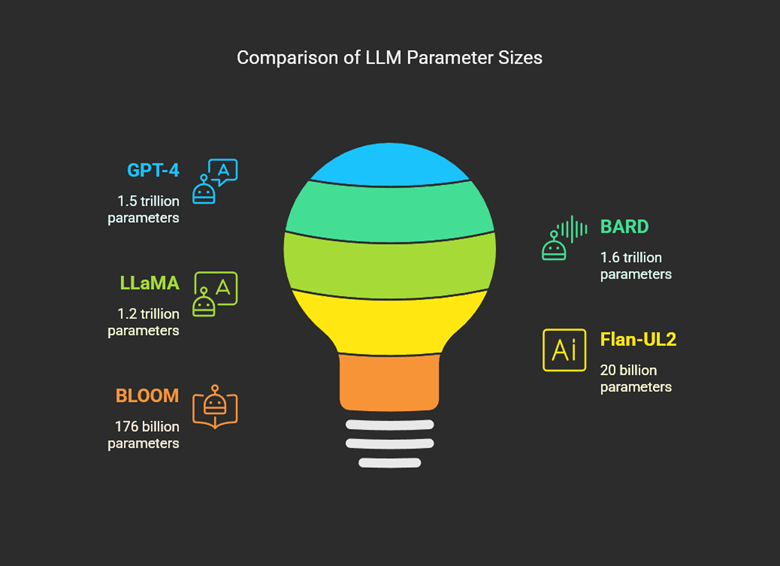
Understanding LLM Parameters
LLM parameters refer to the internal configurations and values that these models learn during their training process. These parameters, which include weights and biases, are adjusted to minimize prediction errors and enhance the model’s ability to generate or comprehend text effectively.
Limitations of CPUs in Processing LLMs and Graphics Rendering
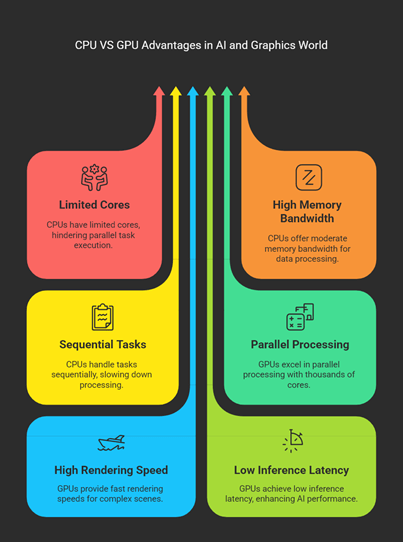
Central Processing Units (CPUs) face significant limitations when handling LLMs and graphics rendering due to their architectural design. Key constraints include:
- Resource Constraints: CPUs typically have fewer cores and lower memory bandwidth compared to Graphics Processing Units (GPUs). This limits their capacity to handle the high computational demands of LLMs and graphics rendering.
- Sequential Processing: CPUs execute instructions sequentially, which can lead to prolonged processing times for large datasets and complex computations.
The Role of GPUs in Enhancing Performance
GPUs are optimized for parallel processing, featuring thousands of cores and higher memory bandwidth. This makes them particularly adept at handling tasks that require simultaneous execution of multiple operations, such as graphics rendering and LLM computations.
Are you curious about knowing and understanding the essential backbone of AI/ML i.e. HPP with detailed step by step guide and code-centric approach, please do check-out AstroMediComp’s HPP Seminar!
You know the best part; it is going to be conducted in Hindi!
Seminar Registration Link:
https://www.astromedicomp.org/hpp-cuda-seminar
Important things to know before registration!


Leave a comment